You have just read a blog post written by Jason McIntosh.
If you wish, you can visit the rest of the blog, or subscribe to it via RSS. You can also find Jason on Twitter, or send him an email.
Thank you kindly for your time and attention today.
Yesterday, while making preparations for my Saturday visit to the WordPlay festival in Toronto, I looked at the download page for The McFarlane Job, a short interactive fiction of mine included in this year’s WordPlay showcase. Here’s what the game’s collected ratings look like, as seen in the Massively app (which one needs to obtain and play the game):
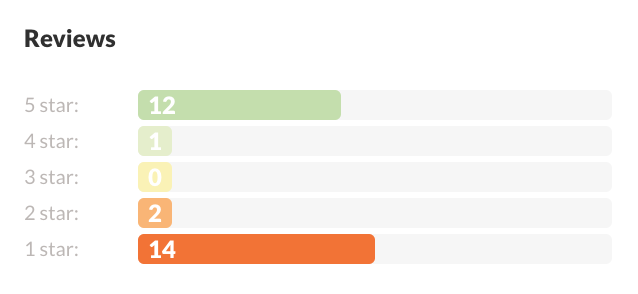
These numbers don’t make me sad at all — in fact, they pleased me more than a little, for two reasons.
Firstly, I know how public, ongoing rating systems like this work. I don’t read these ratings as evidence that 13 people thought my game an epitome of text-game craftsmanship while 16 others found it among the most painful experiences of their lives. Rather, of 29 people who cared to provide an opinion, 13 people liked it, and the rest didn’t. They simply expressed themselves using the universally tacitly understood way one interacts with star-based rating inputs: 5 stars if you like a thing, 1 star if you don’t. (With 4s and 2s available for those rarer times one wishes to add an asterisk to one’s number.)
Seen that way, these numbers sit fine with me! McFarlane is an experimental work, written on commission to test-drive a specific platform for mobile IF, and furthermore represents a novel attempt on my part to write a linear but still compelling interactive game in “friendly gauntlet” style, as inspired by the recent works of Telltale Games. I can completely understand how it won’t appeal to everyone. (At least it’s short!)
I also allowed myself to feel proud at this little reminder that the Annual Interactive Fiction Competition’s rating systems do not work this way at all. As I have written in its guidelines for judges, people rating IFComp games tend to use all the numbers, creating a rubric where each number between 1 and 10 carries its own meaning. What a gulf exists between this behavior and that found on just about every other subjective, user-driven rating system across the web!
The comp started in 1995, making it older than Netflix, the App Store, and innumerable other online enterprises that prominently feature user-contributed ratings. But, without proper stewardship over the years, it could have allowed itself to fall into these systems’ same typical use-pattern where people tend to give things they like a 10 (or a 5, or whatever represents the local system’s maximum), and things they don’t like a 1, and that’s that. I picked up organization of the competition in 2014, and duly let myself take some credit for managing to not screw up this defining aspect of it. (You can see evidence in last year’s ratings histograms, which each far more resembles an “n” than a “u”.)
Giving this comparison more thought, though, reveals an important and more subtle distinction between IFComp-style and Amazon-syle ratings. In the former case alone, nobody can see the “horse race” of the ratings’ accumulating sums or averages during the competition’s six-week-long judging period. We reveal all the games’ ratings (and therefore the identities of the winningest games) only when judging ends, after which no further ratings occur.
As such, judges cannot base their ratings on the games’ current standings or averages. An IFComp judge cannot see that a game they like is struggling in the rankings, and feel tempted to give it a 10 instead of a 7, seeking less to express an individual judgment than to nudge the game’s average score in the “right” direction. Nor do they have strong reason to tie a 1 to a game they might otherwise give a 4 to, if they feel it utterly undeserving of its first-place position.
Compare to ongoing and ever-public ratings systems. These resemble a competition of a different sort: me, the person who just tried this app or watched this movie or whatever, versus the rest of the world and all their opinions that are not mine. Here, my goal if anything involves moving the needle, affecting that all-important star-average as much as I can, and that means casting a rating at one extreme or the other. Anything else would feel quite meaningless, like reciting team-supportive poetry at a football match while everyone else is simply cheering or chanting together.
There might be other reasons to go all-5 or all-1 too, particularly if I know that my ratings help tune a recommendation engine. I have every reason to want to provide this algorithm a boolean reduction of my opinion, not a wishy-washy in-between number!
The IFComp’s ratings continue to work as well as they do mostly due to the fine levels of care and taste displayed by its many dozens of judges. But, where I until recently gave myself and my organizational predecessors the rest of the credit, I now have greater appreciation for how much the basic nature of the closed-booth vote helps maintain meaning for the ratings. This is simply one of those times where, through temporary secrecy, we achieve greater permanent objectivity.
To share a response that links to this page from somewhere else on the web, paste its URL here.
If you enjoy Fogknife, you might also like these websites. (See also an expanded edition of this list.)
 jmac@jmac.org
jmac@jmac.org @jmac@masto.nyc
@jmac@masto.nyc